今回紹介したいのはちょっと変わったものでBeckhoffのTF4500 TwinCAT Speechです。そのTFを使用することによって”人間”と”機械”の間で音声の入力や出力で交流することが可能になります。もちろん、その動きは英語限らず様々な言語にも対応しており、これから設備や製造現場にもっと入れるではないかと。
TwinCAT Speechは以下の機能提供できると期待しています:
- PC-Base Controllerからの音声出力
- Microsoft SAPIがSupportする言語の音声入力・出力
- Amazon Pollyの音声出力
OfflineアプリケーションならMicrosoft SAPI使ってもよし、Onlineで課金できるアプリケーションならAmazon Pollyでもよい。
TwinCAT Speechは2つの重要な部品から作られています。それはASR(Automatic Speech Recognition)とTTS(Text-to-Speech)です。ASRは音声認識でTTSは音声出力になります。その2つの部品は次に説明したいと思います。
System Requirement
注意するのはVisual Studio のバージョンとTwinCAT HMI のバージョンです。

Sound Card Test
TF4500を入れる前に、まずSound CardをTestしてみましょう。
Control Panelを立ち上げます。

Speech Recognitionをクリックします。

Text to Speechをクリックします。

Voice selectionで音声出力を選び、Preview Voiceで音出れるかどうかをCheckしましょう。

Install
TF4500 Speech以外に、TF2000 HMI Server・.NET Runtimeもインストールする必要があります。
TF4500
以下のLinkからインストールEXEをダウンロードします。

しばらく待ちます…

Next>します。
ライセンス同意し、Next>します。

Next>します。

Installします。

しばらく待ちます…

よし、TF4500インストールOKです。
HMI Server install

英語を選び、OKします。

しばらく待ちます…

Next>します。
ライセンス同意し、Next>します。
User NameやOrganizationを入れて、Nextします。
Completeが無難ですので、Next>します。
Installします。

またしばらく待ちます…
TF2000 HMI ServerもインストールOKです。
Visual Studio download
2017・2019年バージョンをダウンロードしましょう。
https://my.visualstudio.com/Downloads?q=visual%20studio%202017&wt.mc_id=o~msft~vscom~older-downloads
.NET Runtime Install
下記のLinkでダウンロードしてください。
もしくはMS Visual Studioからにもインストールできます。
https://dotnet.microsoft.com/download

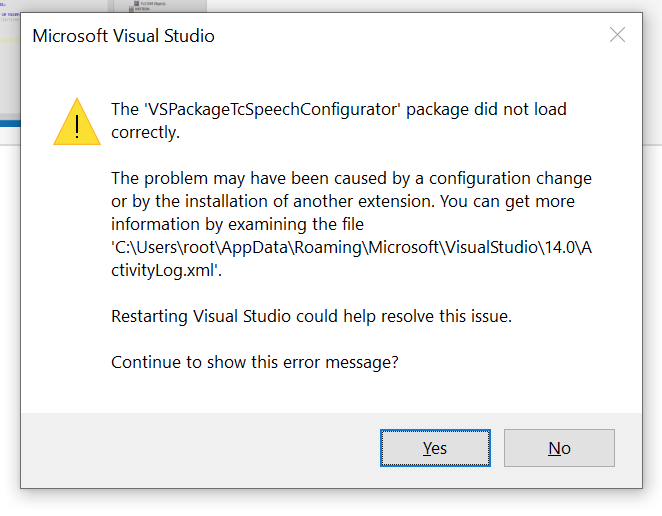
Microsoft Visual Studioエラー
もし以下ののように、
VSPackageTcSpeechConfigurator package did not load correctly
出てきたらVisual Studioのバージョンが2017以上かどうかを確かめてください。
コンセプト
TwinCAT SpeechはWindowsのSound-Cardを使用しSpeechのInput/outputを行います。(もちろんUSB認識できるUSBでもよいです)。TwinCAT Engineering systemからSpeech Configurator使用し構成します。そして構成FileをTarget-SystemにDownloadしTwinCAT SpeechがSAPIやPollyでTTS・ASRを行います。そして音声Input/OutputをTarget-SystemのSound Cardとやりとります。
HMI Server側は今回は触れませんのでまた次回説明させていただきます。
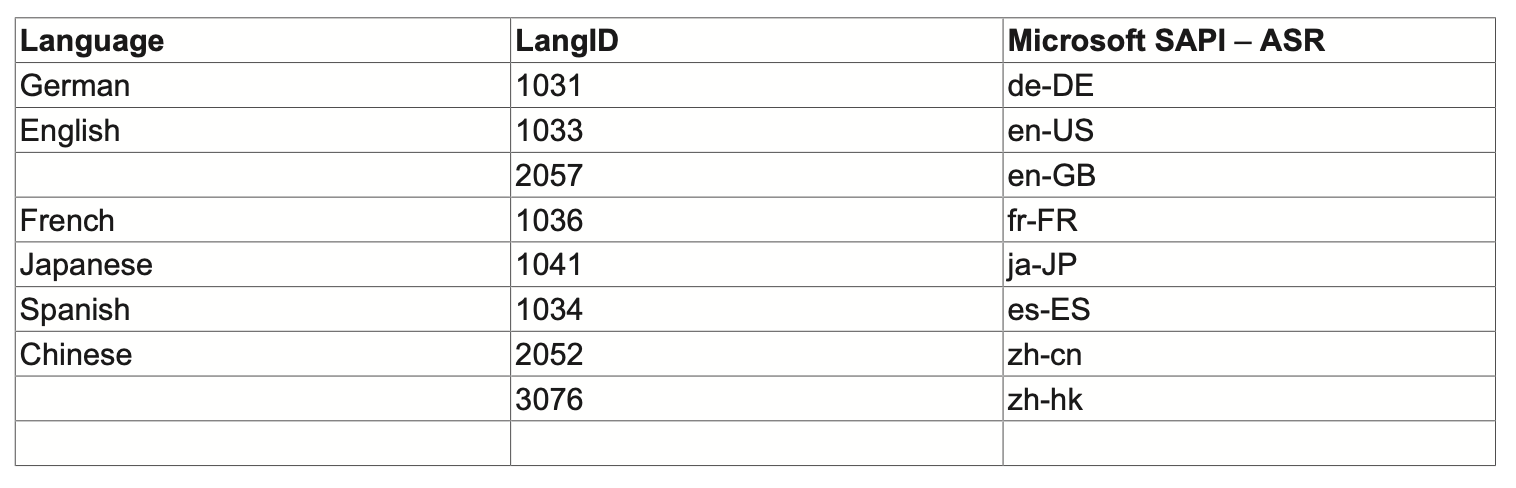
ちなみに、SAPIはSpeech Application Programming Interfaceのことで、Microsoftが提供してる音声APIです。このAPIを使用することよってインタネットとつながってない状態でも音声認識や出力できようになります。(言語はインストールすれば追加できます。)

Support ASR
ASR=Automatic speech Recongnitionのことです。つまり自動音声認識で会話の音声をテキストに変換する技術でありこの技術を使用し音声を検出し、単語として認識させます。
Support TTS
TTS=Text-to-Speechのことで人間の音声を人工的に作り出すのことです。その音声によって合成されたものは合成音声だと言われます。
例:MACのSiri、AndroidのGoogleアシスタント、Amazonのアシスタントなどです。

Function Block
FB_SpeechRecongnition
こっちらは音声認識のFunction Blockになります。
基本bListenをTrueし、nConfigurationIdがさえ間違えなければ音声認識が始まります。

| VAR_INPUT | ||
| bListen | BOOL | 立ち上げで音声認識始まり |
| nConfigurationId | UINT | ASR Configuration IDに参照 |
| VAR_OUTPUT | ||
| bBusy | BOOL | |
| bError | BOOL | |
| nErrorId | ETcsSpeechCommandExitCode | エラー情報 |
| eRecognitionEngineState | ETcsRecognitionEngineState | 現在音声認識エンジンの状態 |
| fRecognitionConfidence | REAL | 最後の音声認識データの精度 |
| nLastCommandExitCode | UINT | 最後実行のExit Code |
| sRecognitionTag | STRING(255) | 最後音声認識のTag |
| sRecognitionRule | STRING(255) | 最後音声認識のRules |
| sRecognitionUtterance | STRING(4095) | 最後音声認識のText |
FB_TextToSpeech
こちらは音声出力のFunction Blockです。
bSpeackがTrueになるとnConfigurationId(TSS ID)とnLanguageId(1033..etc)に参照し
音声出力したいテキスト(sUtterance)をSound Cardから出力します。

| VAR_INPUT | ||
| bSpeak | BOOL | Trueの立ち上げで音声出力始まる |
| sUtterance | STRING | 音声出力のテキスト |
| nConfigurationId | nConfigurationI | TSS ID |
| nLanguageId | UINT | Default=0、TSS構成のDefault言語です。 |
| VAR_OUTPUT | ||
| bBusy | BOOL | True=実行中 |
| bError | BOOL | True=Error |
| nErrorId | ETcsSpeechCommandExitCode | Error内容 |
| nLastCommandExitCode | UINT | 最後音声出力のExitCode |
| nPlaybackPosition | ULINT | 現在音声出力のPosition |
| nPlaybackTotal | ULINT | 音声出力の長さ(ms) |
Example
TwinCAT Speech Configurator追加
File>New>Projectします。

TwinCAT Controller>Empty TwinCAT Controller Projectを追加します。
それでTwinCAT Controller1が追加されました。
次はAdd>New Itemします。
TwinCAT Speech Configuratorを選び、Addします。

それでSpeech Configuratorが追加されました。
ASR
Configuration追加
先追加したTwinCAT Speech Configuratorを右クリックしStart ASR Wizardします。
+ボタンで新規構成を追加します。

このような画面が出てきます。
入力デバイスや音声Levelやテストができます。

Select Deviceで音声入力するデイバスを選び、隣のマイクボタンをクリックしますとパソコンがマイク入力認識できるかどうかを確認できます。

問題なければSaveします。

Service 追加
次はASR Service構成画面に入ります。
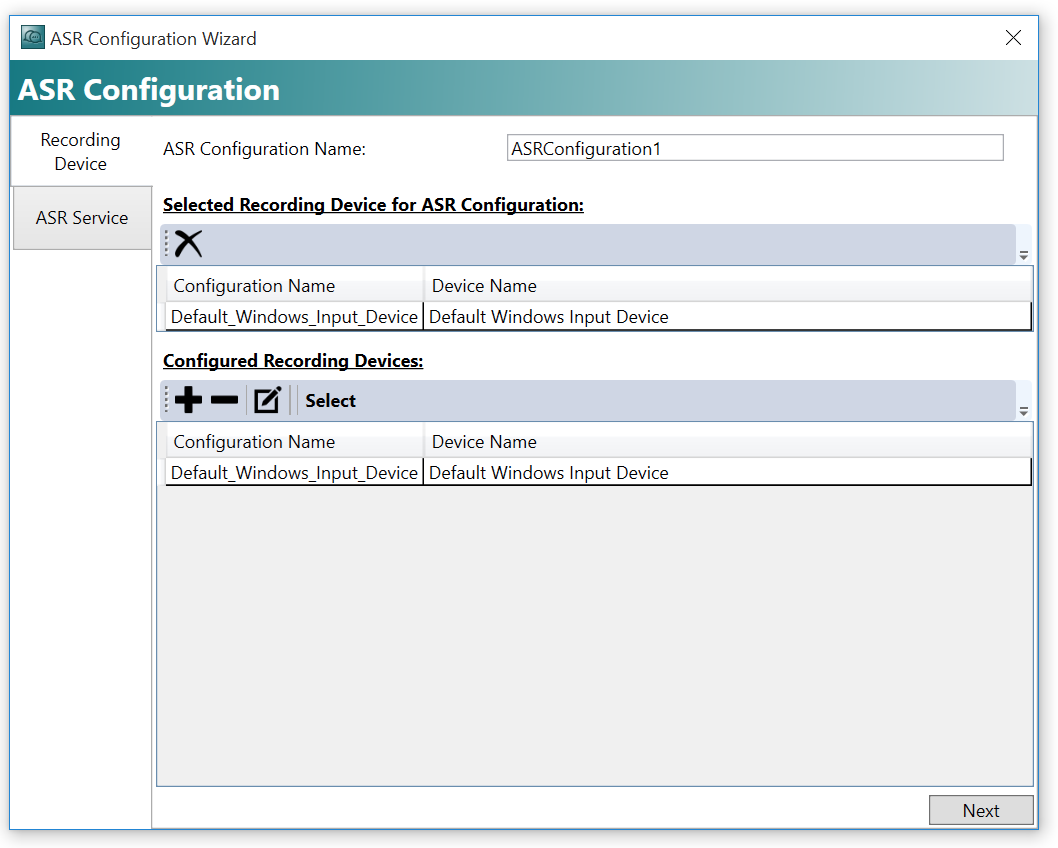
+ボタンで新しい構成を追加します。
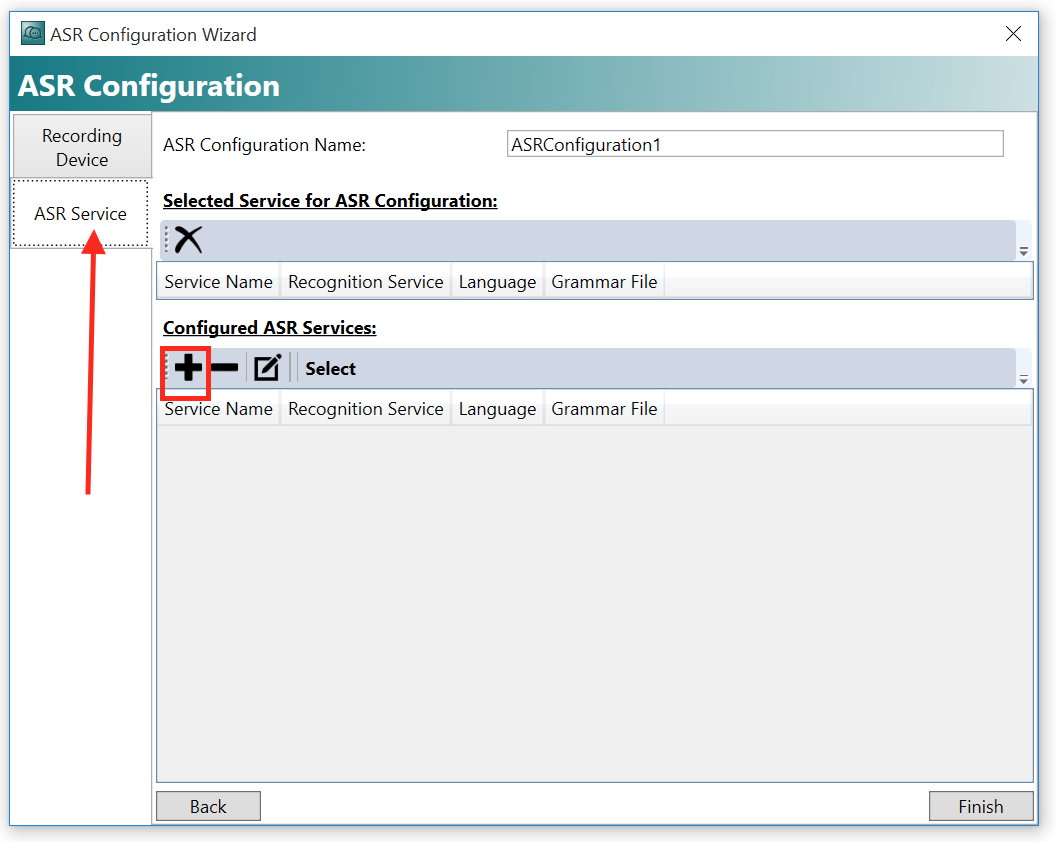
Grammar File追加
ASR Service Nameを入れます。
次はGrammar Fileを追加します。+ボタンをクリックします。
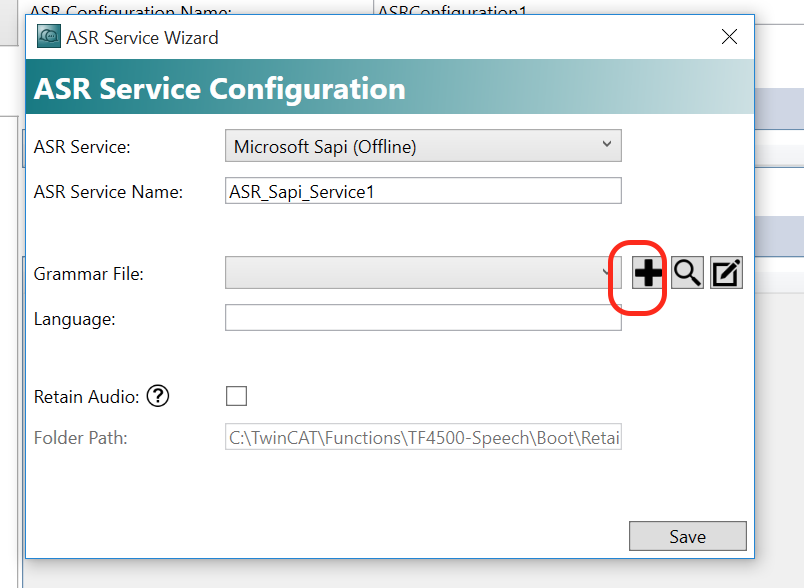
そこでCreate new Grammar Fileをクリックします。
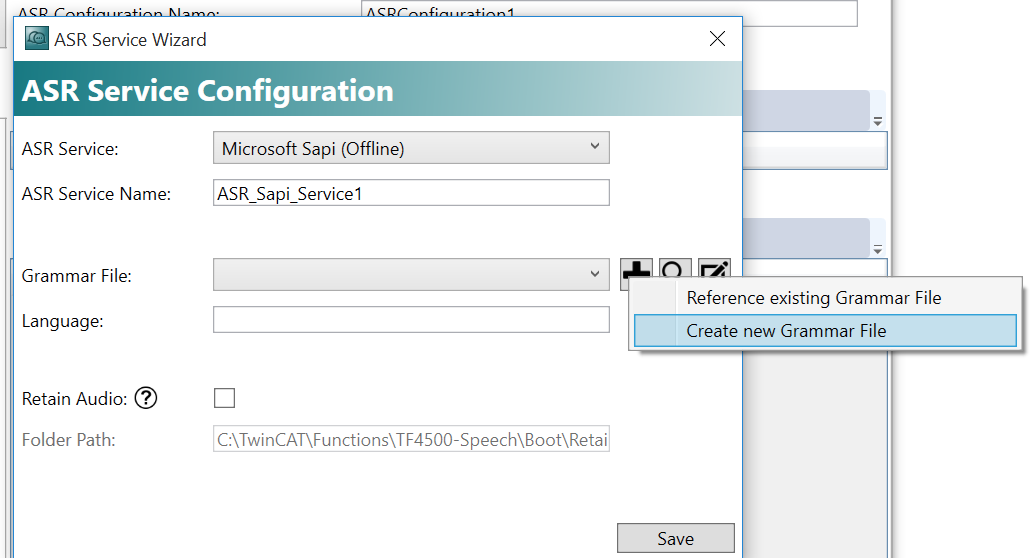
Default Languageを英語にします。
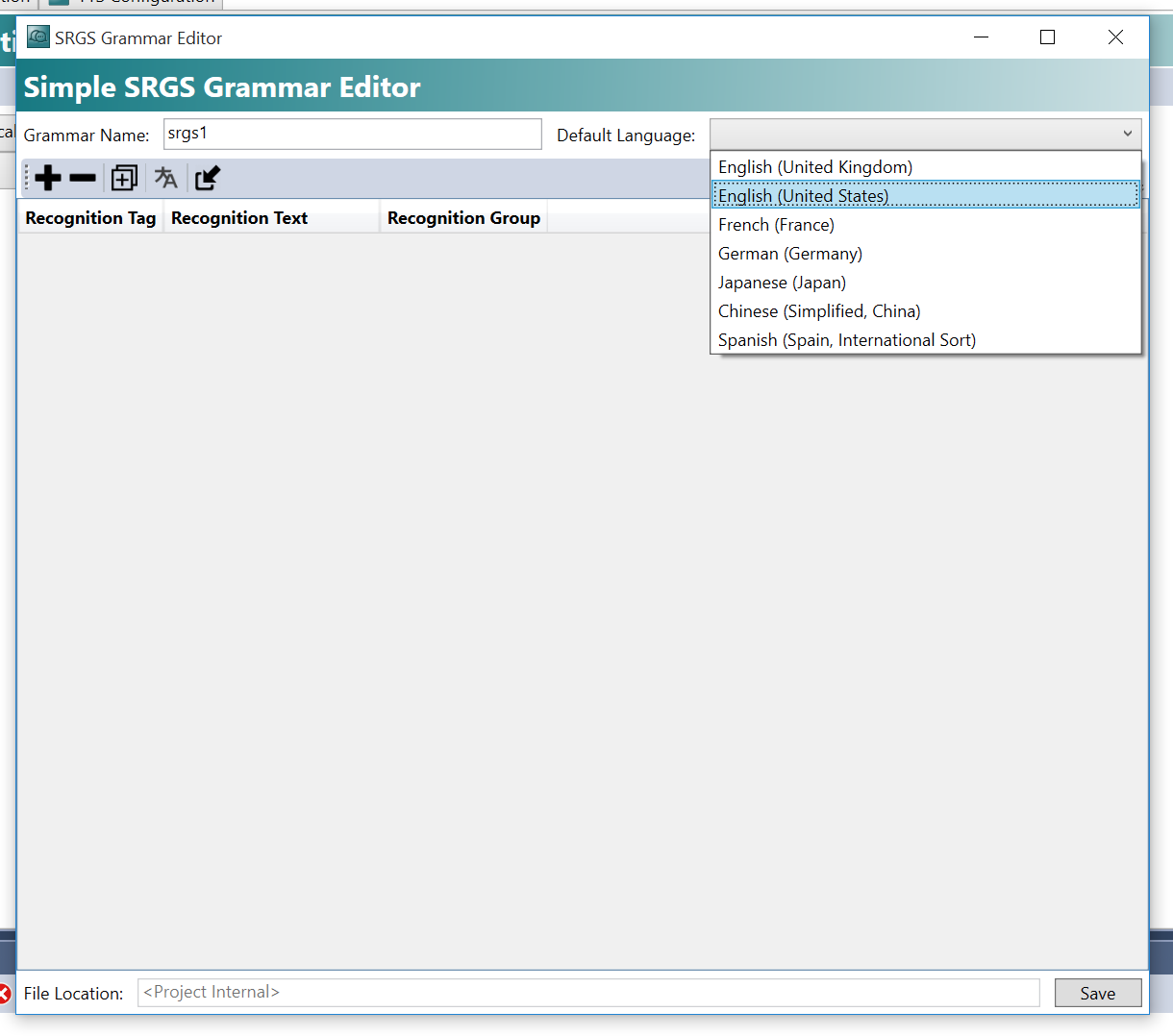
+ボタンで新しいGrammar を追加します。
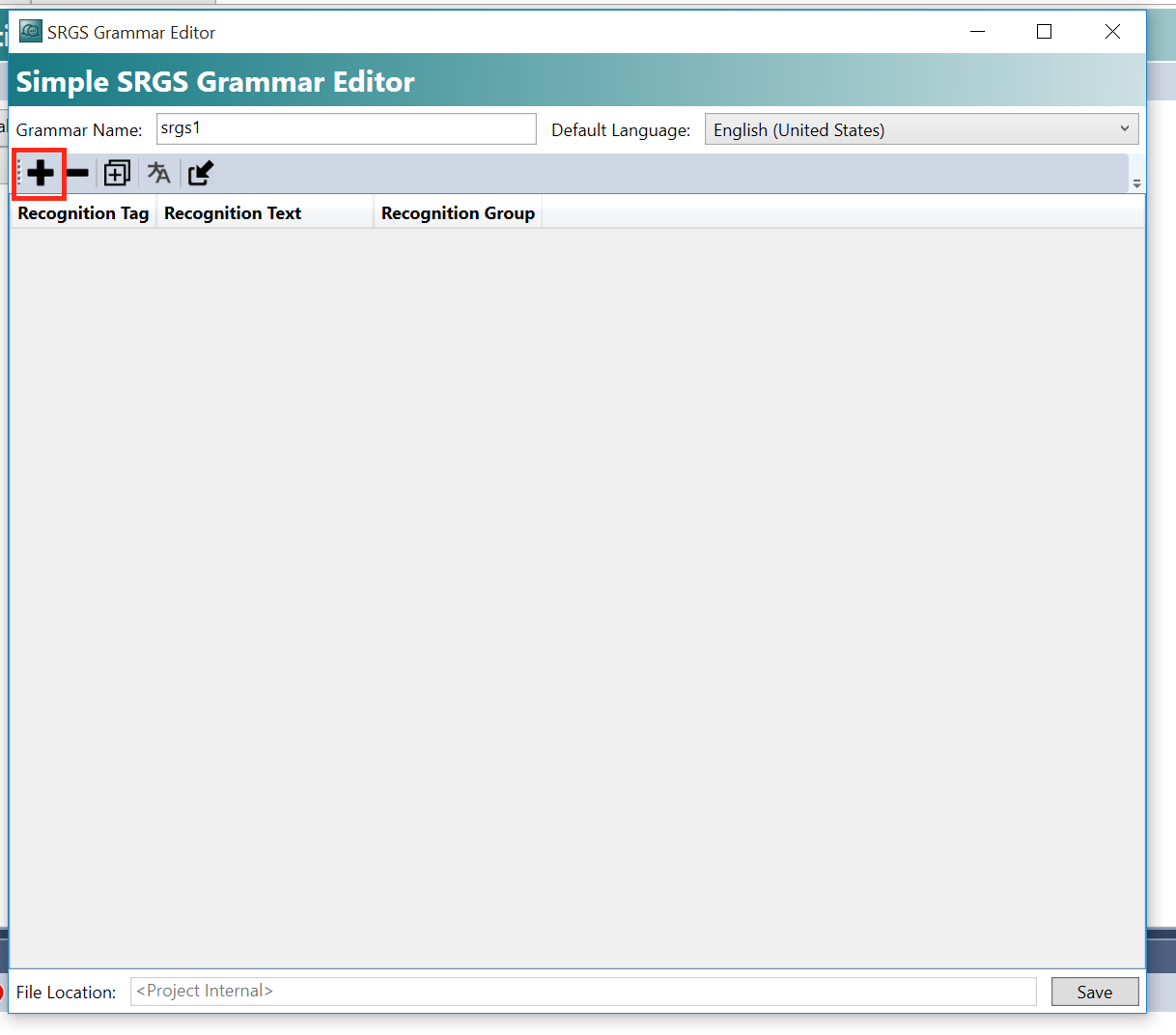
ここで3つの項目がありますね。
Recognition Tag・Recognition Text・Recognition Groupです。
設定終わったらSaveします。
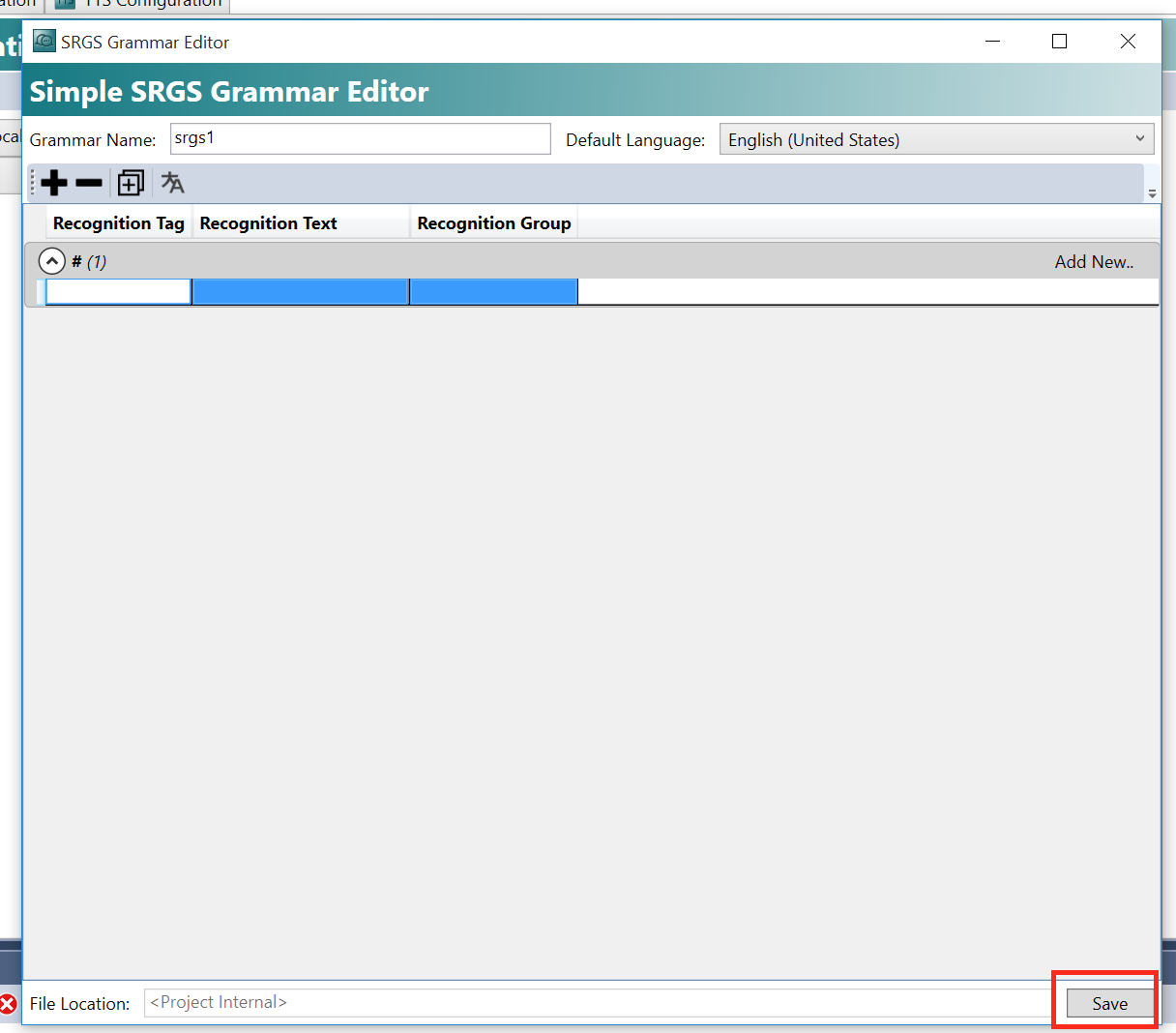
たとえば、以下の例だと、
もし音声認識(Recognition Text)から”Good Morning”だと認識されたら、そのTagは”Say_Good_Morning”の”Recognition Tag”だと分類され、Groupは”OpenCommand”です。
Groupはきれいに切り分けるためです。Mustではありません。
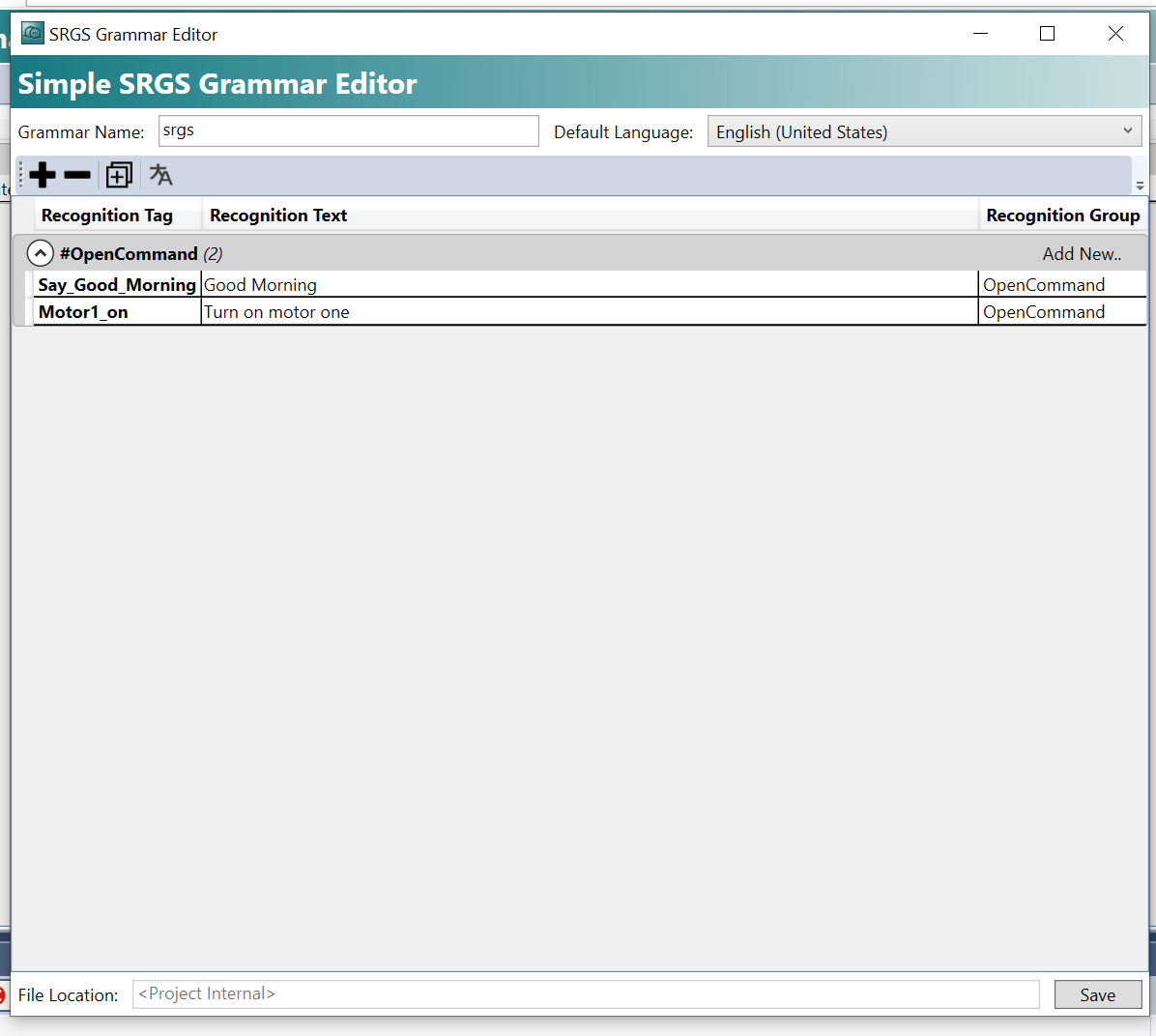
もう一度Saveをクリックし構成を保存します。
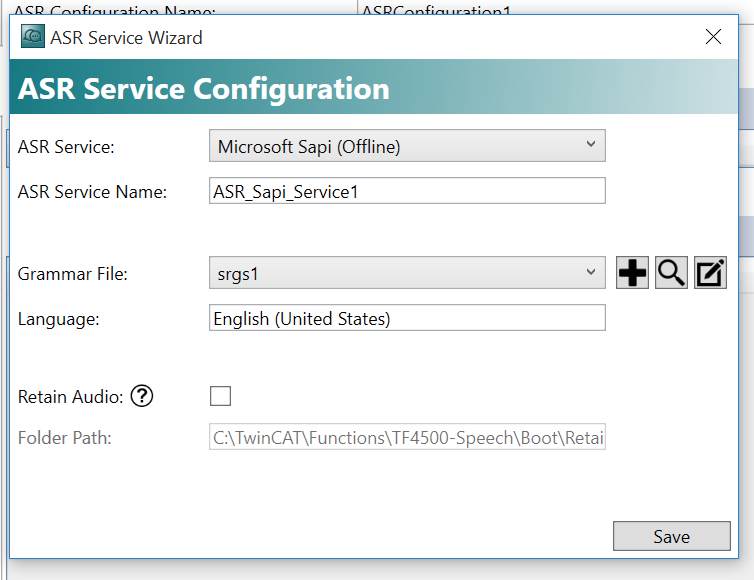
最後はFinishボタンクリックし、ASR構成を完了します。

TSS
Configuration 追加
次はTTSのほうですね。TTSを右クリックし、Start TTS Wizardします。

+ボタンで音声出力のデバイスを設定します。

このようなPopupが出てきます。
ASRと似てる設定なので、詳しく説明しません。

それで設定OKです。

Service 追加
TTS-Serviceで+ボタンをクリックします。
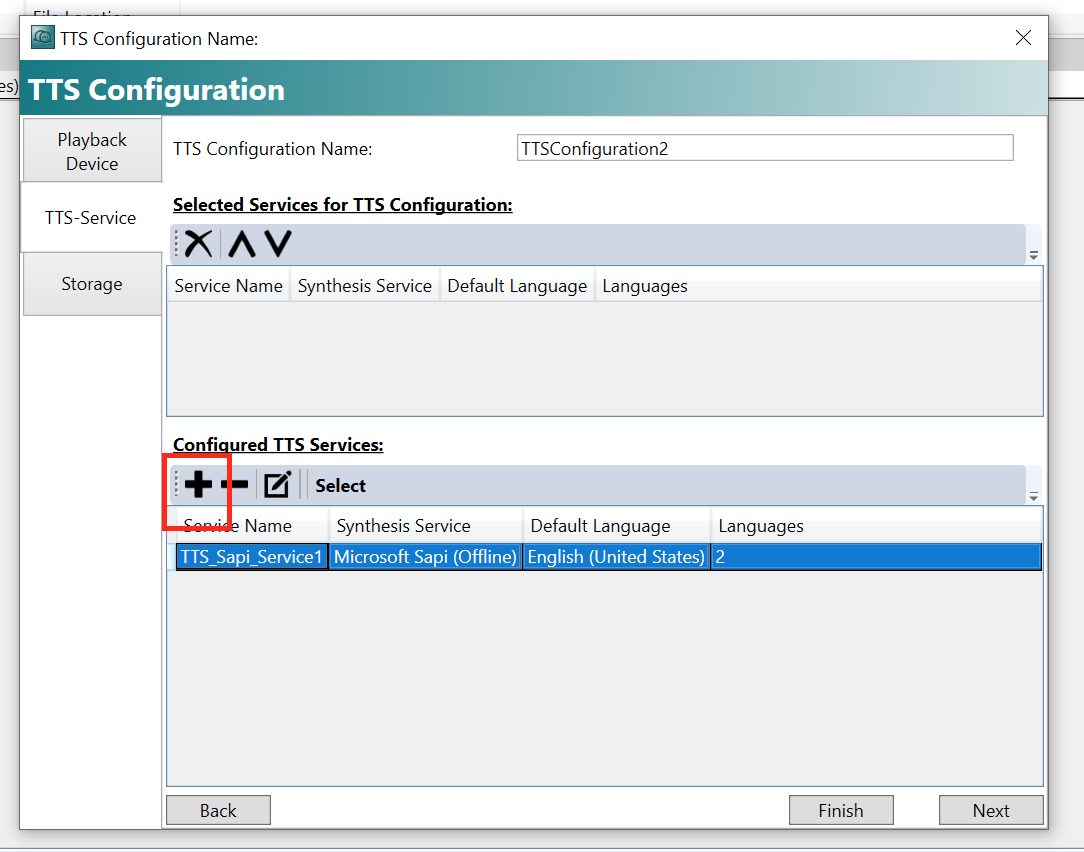
このような画面出てきます。

TTS Synthesis ServiceはSAPIかAmazonのPolly使うか。
今回はSAPIします。

そうするとTTS Service Nameにも自動振り分けます。

次は1 LanguageのところにEnglishを選択します。

2Voicesに表示変わります。
DavidさんやZiraさんどっちにしましょう。
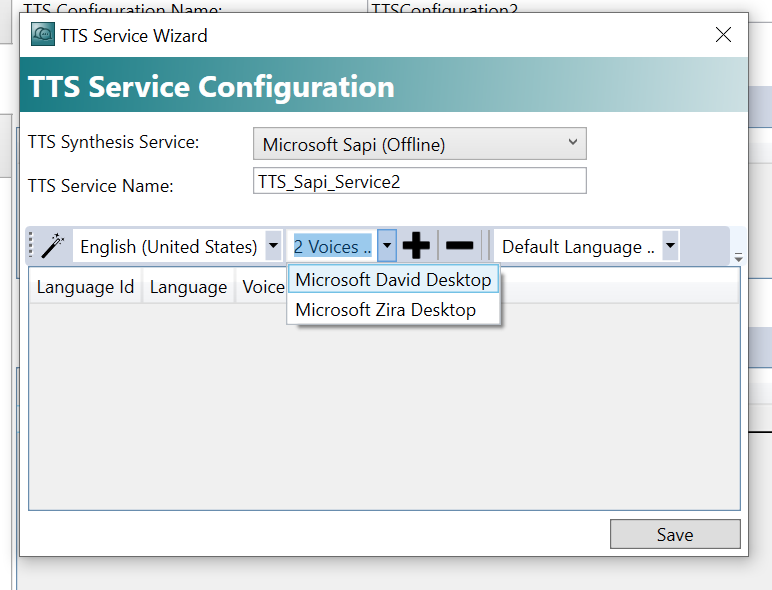
最後は+ボタンで追加します。

それでOKです。Saveします。

Storage
今回は触りませんので、そのままします。
Finishで構成完了させます。

ASR Configuration Id
このIDはプログラム内で使用しますので、メモしてください。
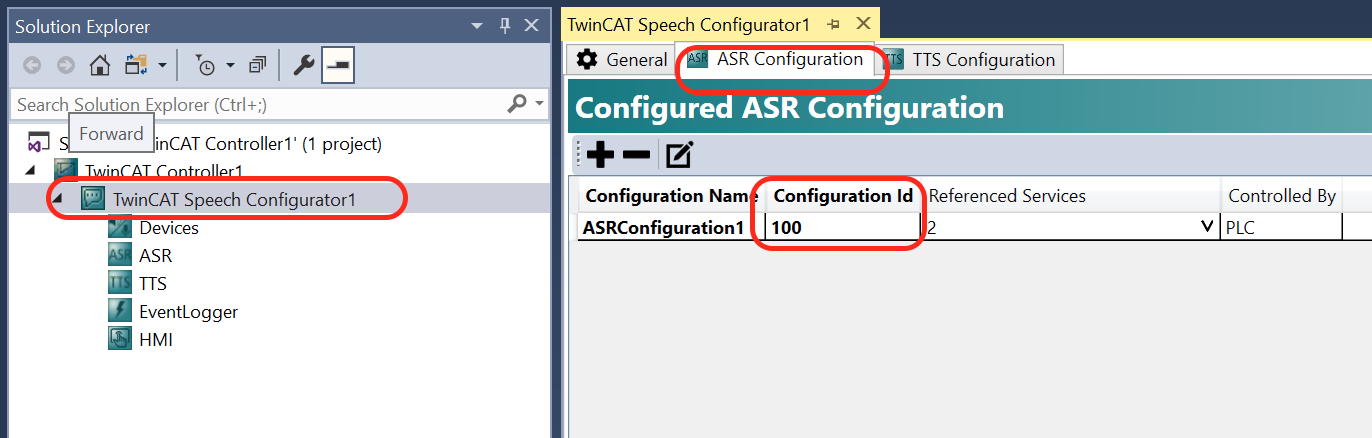
TSS ID
同じくTSS IDも。
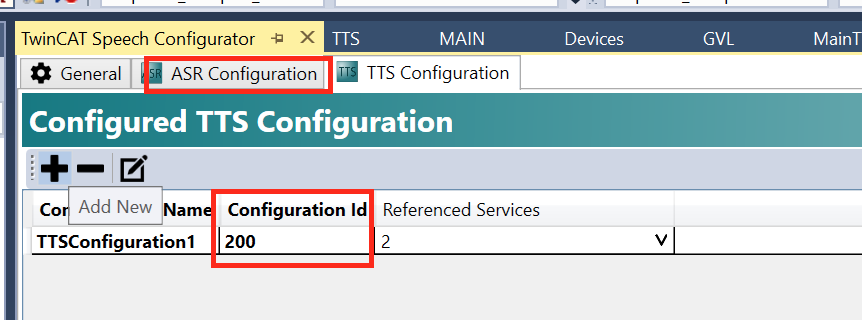
Activate Configuration
最後はGeneral Tabを開いて、Activate Configurationします。

古い構成が上書きされますが、いいですか?
はい。
OKします。
それでSpeech側がOKになります。
TwinCAT Project追加


Add library
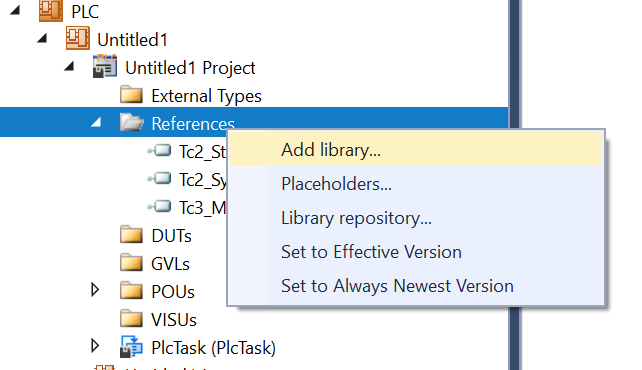

Error?

PROGRAM
今回は参考プログラムから改造したものになります。
認識された音声によって出力も違う。それだけです。
MAIN_ASR
注意するのはnConfigIdASRです。ASR ID合わせてください。
VAR
| VAR // Start speech recognition by setting to true bListen : BOOL := FALSE; bRecognition : BOOL; // ASR Configuration nConfigIdASR : UINT := 100; fbASR : FB_SpeechRecognition := (nConfigurationId := nConfigIdASR); // ASR Variables nLastRecoId : ULINT := 0; timer : TON; END_VAR |
Code
fRecognitionConfidence>0.7は精度は0.7より高いのことです。
あとはsRecognitionTagをGVL.cmdに転送するのはMAIN_TSSで使うためです。
精度低すぎるにも仕方ないでしょう?
| // Set bListen to true, to start speech recognition fbASR(bListen := gvl.bListen, nConfigurationId:= nConfigIdASR); // If new recognition is available and recognition confidence is high enough (over 70%) set bRecognition to true IF nLastRecoId <> fbASR.nRecognitionId THEN nLastRecoId := fbASR.nRecognitionId; IF fbAsr.fRecognitionConfidence > 0.7 THEN bRecognition := TRUE; END_IF END_IF // Keep bRecognition true for just a second IF bRecognition THEN gvl.bSpeak:=TRUE; gvl.bListen:=FALSE; gvl.cmd:=fbASR.sRecognitionTag; timer(IN := TRUE, PT := T#1S); IF timer.Q THEN timer(IN := FALSE); bRecognition := FALSE; END_IF END_IF |
MAIN_TTS
注意するのはnConfigIdTTSとnLanguageIdです。
TTS IDと言語設定に合わせてください。
VAR
| VAR // TTS Variables bSpeak : BOOL := FALSE; {attribute ‘TcEncoding’:= ‘UTF-8’} sText2Speech : STRING(4095) := ‘<speak>Hello world!</speak>’; // TTS Configuration nConfigIdTTS : UINT := 200; nLanguageId : UINT := 1033; fbTTS : FB_TextToSpeech := (nConfigurationId := nConfigIdTTS, nLanguageId := nLanguageId); END_VAR |
Code
GVL.cmdによって出力の音声が違うだけです。
| IF gvl.Cmd = ‘Say_Good_Morning’ THEN sText2Speech:=’<speak>Good morning Sir. I am your TwinCAT system help. What can i Help you?</speak>‘; ELSIF gvl.Cmd = ‘Motor1_on’ THEN stext2Speech:=’<speak>OK. I get your order and turn on the motor 1 after 5 seconds.</speak>‘; END_IF fbTTS(sUtterance := sText2Speech, bSpeak := gvl.bSpeak, nConfigurationId:= nConfigIdTTS); IF NOT fbTTS.bBusy THEN fbTTS(sUtterance := sText2Speech,bSpeak := FALSE, nConfigurationId:= nConfigIdTTS); bSpeak := FALSE; gvl.bSpeak:=FALSE; END_IF |
MAIN
Code
| MAIN_ASR(); MAIN_TTS(); |
結果
自分の英語はちょっと汚いですがそれでもちゃんと認識してくれて嬉しいです。
Sample Codeは以下でダウンロードしてください。
https://github.com/soup01Threes/TwinCAT3/blob/main/Project_TF4500_1.tnzip
はーい、お疲れ様です。
もしなにか質問あれば、メール・コメント・Twitterなどでもどうぞ!
Twitterのご相談:@3threes2
メールのご相談:soup01threes*gmail.com (*を@に)